
Modern AI systems love data: proprietary models, customer prompts, sensitive training data, medical records, financial data and intellectual property that can’t leak without consequences. Workloads currently run on infrastructure that assumes trust in cloud operators, hypervisors, and humans we never meet. Encryption protects data at rest and in-transit, but the moment a model loads into memory or instructions hit the bus, those protections disappear.
This is the AI privacy paradox: the more valuable and capable our models become, the more exposed our trusted data is.
Confidential computing emerges not only as a security enhancement, but as a practical response to this gap proving that AI workloads are executed exactly as intended, by parties we intended, even on infrastructure we do not own.
With all the buzz about data privacy in the age of AI and advanced LLMs, Confidential Computing(CC) has become a bubbling topic in deep tech circles. The origins of commercial CC are traced to the early 2000s when several of the major computing vendors discussed creating subprocessors that could attest to system integrity. Originally the talks were around how to ensure secure system boots, but evolved to include hardware security using Trusted Platform Modules (TPMs).
Eventually secure enclaves and compute environments made their way into primary CPUs and were used for Digital Rights Management (DRM), preventing copying your favorite episode of Silicon Valley(HBO) to share with friends. During the 2010s there were many use-cases explored using secure compute: Digital Identity, trusted data supply chains, and most notably message signing with symmetric keys. Later in the 2010s we started to see mobile devices and virtualization features using Trusted Execution Environments / Secure Enclaves: entirely separate from the primary host CPU and memory, providing a clean, unimpeachable space for processing to occur.
Most training and fine-tuning workflows include aspects of digital identity to personalize and contextualize interactions. Even if using RAG and keeping certain information in a VectorDB, leakage often occurs with the training data.
During training, all the data that matters is exposed at once. Raw datasets are unpacked, model weights are mutable and constantly evolving. Gradients and intermediate activations encode traces of the data they came from which. Yet in most environments, we still treat training infrastructure as something we simply “trust,” even when it lives in someone else’s data center, under someone else’s access and control. Encryption protects data on disk and in-transit, but the moment training begins and tensors land in memory, those protections fall away.
When a training job runs inside a hardware-backed trusted execution environment, the usual assumptions no longer apply. The host operating system can’t peek into memory. The hypervisor can’t scrape tensors. Even a cloud operator with full administrative access can’t see the data being processed. Training happens inside a sealed space enforced by silicon, not policy, where datasets, weights, and gradients remain protected while the model learns.
One of the most powerful features of this is data no longer has to be handed over blindly. Before any dataset is released, the TEE environment proves what it is. Through attestation, it presents a cryptographic statement describing the exact software, firmware, and hardware configuration it’s running on. Only when that proof matches expectations do decryption keys or access tokens become available. If the environment changes the data stays locked. Training becomes conditional, not assumed.
This matters just as much for models as it does for data. Training doesn’t just consume information; it reveals how a model thinks while it learns. Weight updates, optimizer state, and intermediate representations expose architectural choices and hard-won insights. In conventional setups, these artifacts are visible to anyone who can inspect memory or tap into low-level tooling. Confidential training keeps those internals private, allowing organizations to train proprietary or high-value models without quietly leaking their intellectual property along the way.
There’s also another benefit: risk drops even when no one is actively attacking. Gradients and activations are some of the richest sources of accidental leakage, especially in environments filled with logging, profiling, and observability tools. By keeping memory encrypted and isolating devices through hardware controls, confidential training shrinks the space where mistakes can happen. It doesn’t make learning magically safe, but it makes it far harder to observe or extract anything meaningful from the outside.
And this isn’t limited to small experiments or single-GPU jobs. Confidential training scales. Multi-GPU workloads, distributed data-parallel training, and even federated learning setups can operate within attested environments. The difference is that trust is no longer global or permanent. Each compute training requires the compute nodes to attest and verify they can access the cluster. Going further, when you start to integrate secure and confidential storage systems, such as Storj, you reduce the risk-surface of the pipeline.
Unlike training batches, inference runs continuously. Prompts stream in from users, applications, and systems that expect answers immediately. Those prompts often contain sensitive material: private market data, proprietary documents, internal code, regulated records. At the same time, the model itself represents years of work and enormous investment. In most deployments today, both are exposed the moment inference begins. The model sits in plaintext in GPU memory, user inputs pass through host-managed busses, and everyone involved assumes that no one below the application layer is watching.
When an inference service is deployed inside an attested enclave, the environment proves itself before it ever accepts traffic. The server presents cryptographic evidence of its identity—what code it is running, which firmware it depends on, and whether the underlying CPU and GPU are operating in confidential compute mode. Only after that proof is verified does the service come online. Requests aren’t just routed to a container; they are routed to a space that has already demonstrated it can be trusted.
This changes what it means to serve a model. Weights remain protected in memory while the GPU executes the forward pass. Prompts are decrypted only inside the enclave and never appear in host-visible memory: even operators with full access to the cluster can’t inspect inputs, outputs, or intermediate state. Model owners don’t have to choose between protecting their IP and offering their models as a service, and users don’t have to assume their data disappears into a black box that can be easily compromised the moment it’s submitted.
In the practical-world this fits naturally into modern infrastructure. A confidential inference pipeline can run on Kubernetes, with nodes labeled for confidential compute and GPUs operating in NVIDIA’s confidential mode. When a pod starts, it attests the host and the accelerator, then registers itself with an internal service registry. Traffic flows through encrypted, mutually authenticated gRPC endpoints, ensuring that every request reaches a verified enclave and nowhere else. From the outside, it looks like a standard LLM service.
What’s powerful about this model is that it protects both sides of the interaction at once. Customers can verify that their prompts are processed inside an enclave before they ever send sensitive data. Model providers can be confident that their weights are never exposed to the platform running them. Neither party has to blindly trust the infrastructure in between. Trust is established explicitly, per deployment, and continuously enforced.
Confidential inference doesn’t slow AI down; it makes it usable in places where it otherwise wouldn’t be allowed. It enables AI services in regulated environments, shared clusters, and multi-tenant platforms without forcing impossible tradeoffs. As inference becomes the dominant use-case, the ability to answer a simple question “where did my data actually go?” may matter more than the answer itself.

Confidential Computing is not a single approach, but a class of technologies and patterns that provide confidence in computation. Best practices require that attestation should be present at every step of the process and measurements are constantly performed before, during and after workflows. Security tokens are checkpointed during processing and nonce-based tokens are used to prevent replays.
Common modern hardware requirements include, but are not limited to:
And when working in the GPU and AI space:
There are a variety of emerging configurations across the CC space.
Table 1. CPU/GPU matrix for CC compatibility.
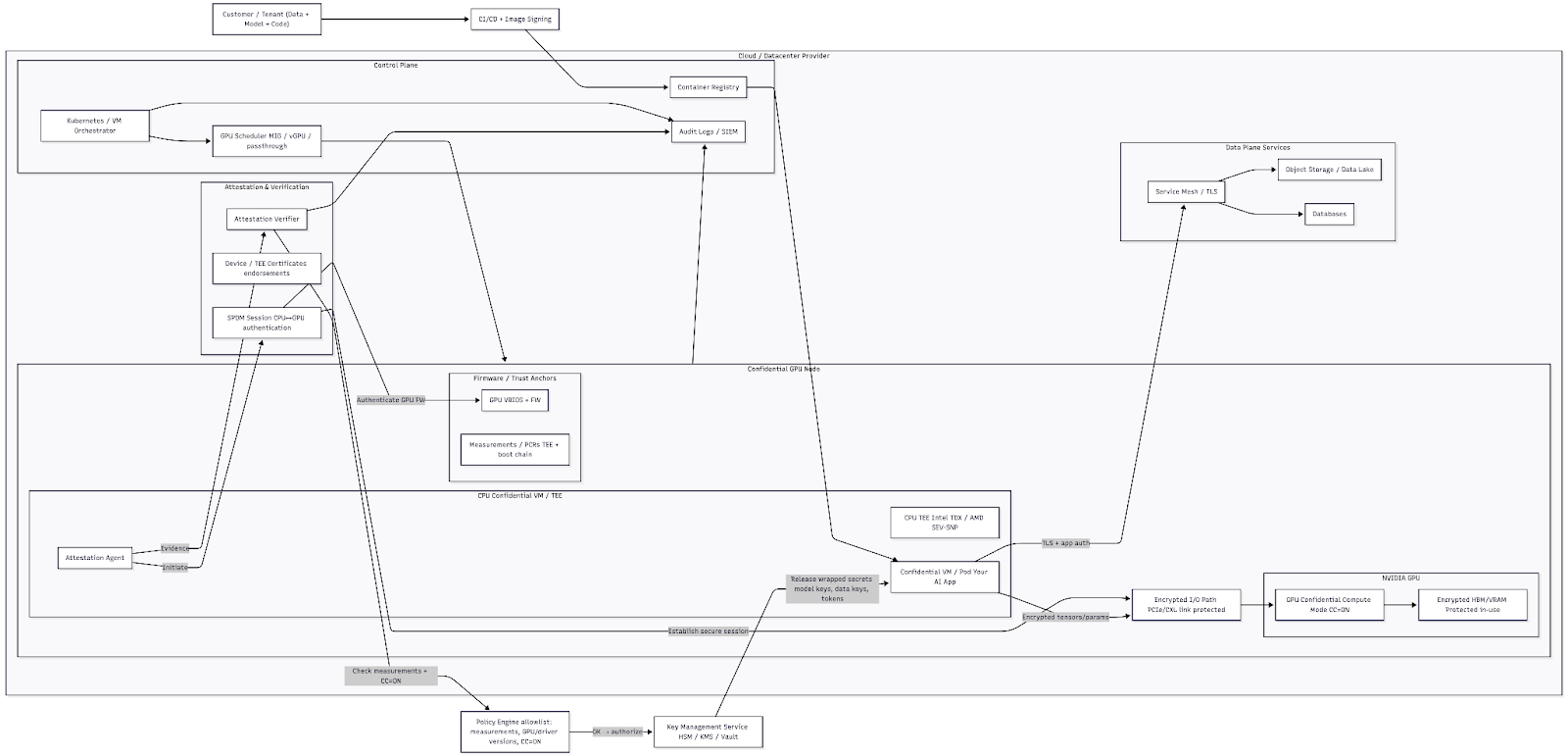
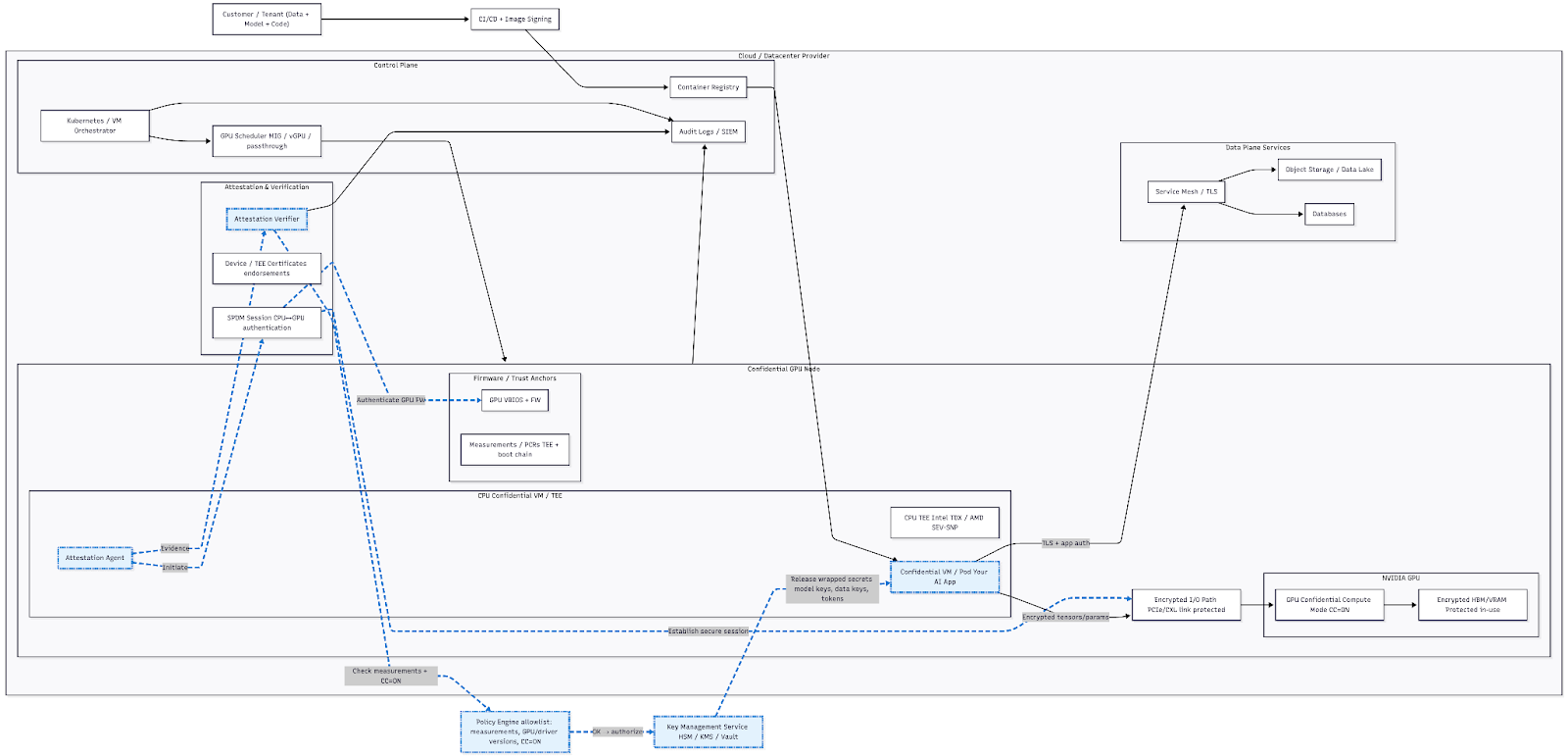
Operational discipline is what separates a secure system from an easily impeachable system. Confidential computing functionality is powerful, but without best-practices it’s easy to have data leak outside of the enclave and build a false sense of security for your deployment.
Enforce Attestation Policies First
Attestation is the first step before any sensitive action occurs. When you’re designing your workflow, define policies that confirm enclave measurements, firmware versions, TEE type (TDX or SEV-SNP), GPU confidential-compute state, and quote freshness. Data access, model decryption, and job startup should all be gated on a successful verification. If measurements drift or quotes expire, access is denied.
Key management always belongs outside the enclave
Secrets are generated and stored in external trust systems and never baked into configs. The enclave proves its identity via attestation and only then does the KMS release a short-lived key. Keys are issued to a single workload, rotated frequently, and confined to the enclave’s lifetime so they are useless if extracted or replayed elsewhere.
Performance needs to be measured
Confidential computing introduces overhead, but it’s usually fractional and can be planned for. CPU overhead under Intel TDX or AMD SEV-SNP typically shows up as higher page-fault and VM-exit costs compared to non-TEE VMs.
On the GPU side use direct PCIe pass-through with IOMMU enabled and confirm the GPU is operating in confidential mode; when configured correctly, H100/H200-class GPUs show minimal performance impact for inference and modest overhead for memory-heavy workloads. CC Inference has about a 5% impact compared to traditional compute and training has up-to ~15%, though YMMV depending on workload. Memory-heavy workloads with lots of writes on the HBM will see the most impact while GEMM inference will see nearly zero impact.4
Observability should rely on the Trust Boundary
Host-based inspection breaks confidentiality; instead, get metrics from the enclave: high-level metrics (latency, throughput, GPU utilization) and error counters. Never capture raw data/tensors, prompts, gradients, or memory dumps. Export metrics over authenticated channels, aggregate them externally, and keep logs deliberately light. If you wouldn’t hand the data to a human, don’t log it.
Benefits and Business Impact
Some industries have obvious security concerns when it comes to regulated data or intellectual property(IP). The reality is that even common cloud compute use-cases (transaction processing, storage, etc.) can benefit from CC features. Some highlights for business impact are:
Security
Protects data-in-use and IP from rogue admins, cloud operators, or compromised hosts
Compliance
Enables processing of sensitive regulated data (HIPAA, GDPR, PCI)
Collaboration
Allows cross-organization training without exposing raw data
Trust
Builds verifiable assurance for customers and partners
Innovation
Unlocks multi-tenant AI and decentralized compute marketplaces
At Valdi we’re always excited to get our hands dirty. For most of 2025 the major OEMs (Supermicro, Dell, HPE) have been in various states of support for NVIDIA confidential computing. Once firmware stabilized around mid-year we started reviewing capabilities using Dell hardware and our TDX demo project. TDX-Demo implements a light-weight framework for initializing, attesting, executing and cleaning-up a workload from a CC GPU environment.
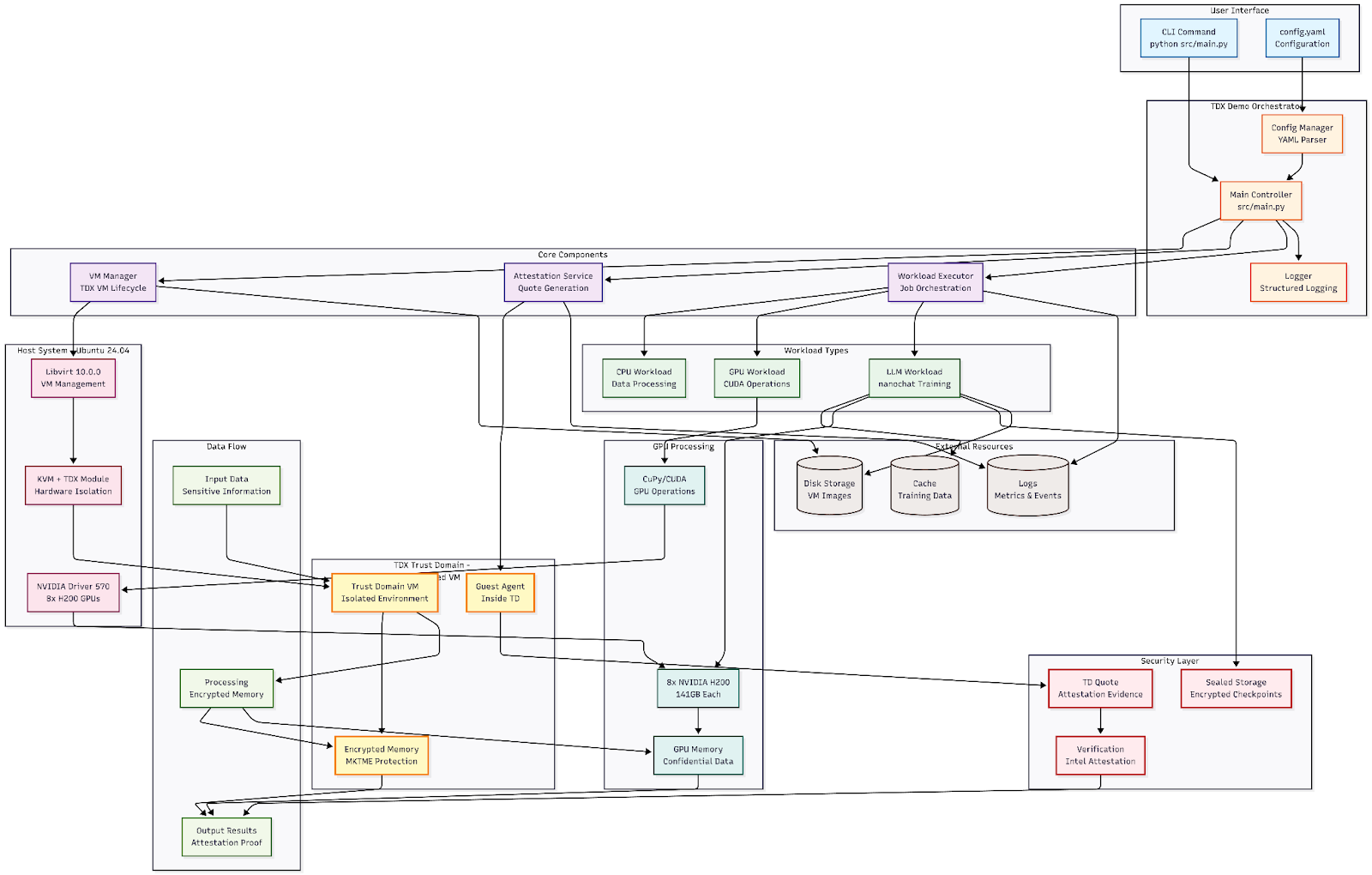
The above shows the logical components of our example workflow. For our example, we:
The project is available at https://github.com/storj/tdx-demo
Toward the end of 2025, there are more projects and articles causing discussion about Confidential Computing and the various applications and capabilities we’ll use it for. Some of the trends for 2026 will likely be:
In addition to wide-spread adoption of CC infrastructure for traditional cloud AI use-cases. We wouldn’t be surprised if traditional CC compute has a resurgence and eats into normal CPU server use-cases.
Keywords: AI, Cloud, LLM, NVIDIA, Confidential Computing, Confidential AI, TEE, Trusted Execution Environment, CC
—
Cites:
[1] Intel TDX Documentation - https://www.intel.com/content/www/us/en/developer/tools/trust-domain-extensions/overview.html
[2] Canonical TDX Guide - https://github.com/canonical/tdx